The Seven Keystones Of Accurate Audio Blind Testing is a walkthrough to properly explain and correct where applicable the concepts of comparing different audio gear in a subjective listening environment.
This article on testing was reproduced from the educational archives of Yuri’s Sample Rate Converter website with his kind permission. All copyright belongs to said website and any reproduction of this information below can only be done with the express permission of Yuri Korzunov.
Myths
“Audiophile myths debunked” is one of the popular topics in various forums and articles. As a rule, these “myths” are based on listening impressions rather than testing. They are unexplained technically or have small measurable differences which may be theoretically / probably.
To accurately check these “myths” it is recommended to use an objective method that ensures reliable repeatability. A result that delivers the same values in similar conditions at a time.
Blind Testing
An audio-blind test is one way of “objectively” measuring the “subjective” perception. We shall discuss then how to turn this type of test into a safe and reliable set of evidence.
A Hi-Fi blind test is a technique in which the listener (participant) tries to recognize an unknown sample via sound only.
A sample here is a recording, or equipment, or software, or an apparatus/software mode. This trial is an attempt to measure a non-measurable music feature we know as perceived sound quality.
The objective aspect here is the methodology by which we can measure and repeat the result in equal conditions.
The subjective aspect here is detected by human feelings/hearing and this results in a decision made by the listener based on what they perceive.
As a tester, we cannot directly access another person’s feelings. We cannot listen to music in the same way as another person. We can ask him/her only but they can’t exactly describe their feeling. Especially in the subtlest details, provided by modern musical equipment, software, or HiFi test records.
But we want to know: it is really audible or not?
Testing Methods
This is the main aim of the blind trial. We try to eliminate the subjective part of perception (price, bias, habit, etc., i.e. probable imaginary perception). For even more “subjectivity” reduction, a double-blind test is used.
Double Blind
A Double-blind test is a trial where neither the listener nor the conductor knows what the sample actually is.
Blind test audio

The ABX test may be used in this scenario. An ABX test is a trial where samples A and B may be compared with sample X (either A or B). The listener should recognize what is X (A or B).
ABX test audio
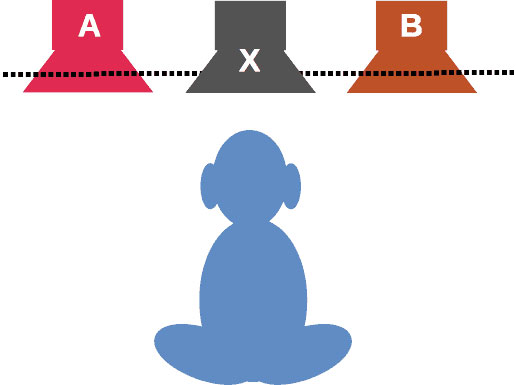
ABX
ABX audio test software
Foobar2000 with ABX test software plugin may be used to ABX test audio files. However, the author doesn’t know what happens with the audio files when ABX-test-foobar’s plugin prepares files before comparison (progress when the plugin starts).
For an ABX test on Mac OS software, you can try to find the ABXer utility. For iOS, there does exist an ABX Tester application. Also available is a cross-platform Lacinato ABX. These programs remain untested with me so I cannot comment further on their features or capability.
If somebody claims that the sound is different, we really cannot measure its audibility. This is because we listen to the audio in the brain via our ears.
Theoretically, measurement tools are more sensitive than human ears. However, without trials, we do not know where is the ‘audibility edge’ of difference.
An Audibility edge is the maximal value of a feature or the difference value between listening samples that cannot be distinguished by a human.
Professional double-blind testing of music equipment is not home entertainment. It is hard long expensive work. It doesn’t necessarily mean that audiophile blind testing should be done at the laboratory. We just need to ensure safe and reliable trial results are delivered in a conducive environment for the testing procedures.
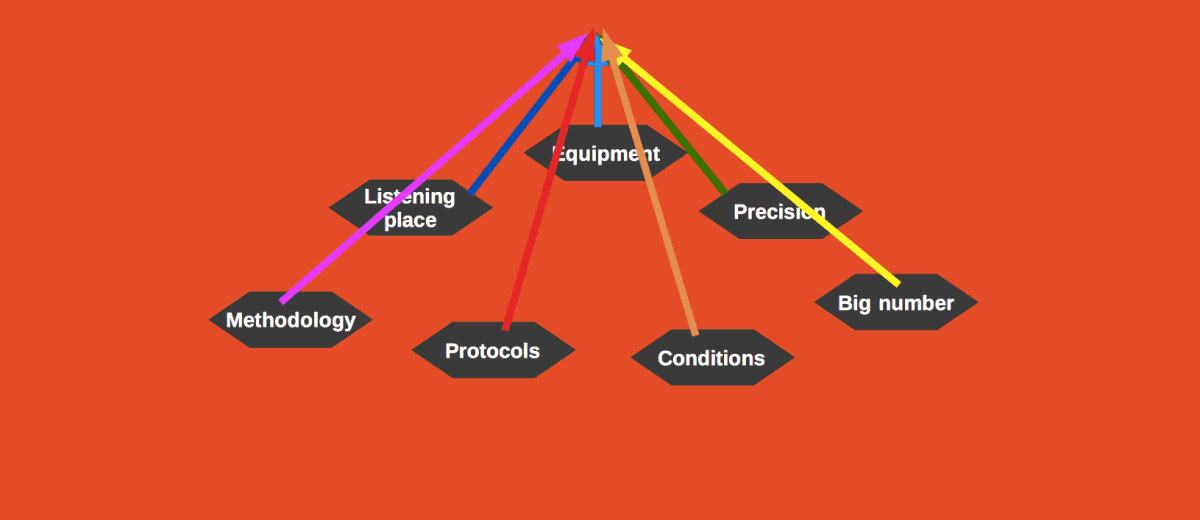
Proper Blind Hi-Fi Test – The 7 Keystones
These features are necessary to provide safe trial results:
- Methodology
- Protocol
- A large number of measurements
- A suitable listening place
- Testing equipment issues
- Measurement precision issue
- Careful condition control
Tests should ensure reliable repeatability under the same conditions. i,e, there should be no deviation from the agreed parameters or set precisions.
Methodology
The trial begins with a methodology design. A methodology defines the trials:
- aim
- precision
- implementation
- other things noted below
The methodology should be designed first
Test protocol
The test protocol is on paper, where detailed data is recorded about the conducted trial. It includes:
- equipment
- measurement tools
- participants (and their listening skills, occupation, education, other)
- trial conditions
- other stipulations as required or specific to the test
Hi-Fi test protocol

The testing and measurement equipment may be registered with a unique identifier of the item (serial number, as an example). The main protocol aim is the ability to check experiment conditions in case of doubt or to better understand the reasons behind any results.
Listening place
To save time, several participants may be accommodated in one room. Several rows of seats may be placed in the room.
In the trial result interpretation, it is necessary to take into account:
- each seat’s positioning and how it impacts the sound,
- the seat with and without the listener will impact differently,
- the speaker sound is different for each seat due to the position.
Speakers have individual radiation patterns. The frequency response depends on the listener’s sitting position relative to the speakers and the listening room’s walls. Acoustical rays can interfere, rays bounced from a surface other than a wall can interfere too.
Impact seat place to audio test results

An anechoic room (free from echo) is ideal to prevent acoustical wave bouncing. Speakers also have different frequency responses in different directions. Therefore, different seat placements can also cause different frequency responses, even in an anechoic room. Generally, only one fixed sitting place in the listening room is recommended for accurate and reliable testing.
Testing equipment issues
Tested equipment (apparatus that will be tested in the trial) should be checked to ensure they are workable under the conditions outlined in the methodology in case of doubt.
It is desirable if testing equipment has a unique identifier (serial number). It helps when we want to repeat the experiment or we find different resulting reasons in case of doubt. Because different equipment instances may have various performance figures and thus sound differently.
One very important thing! The loudness of the compared samples
Human ‘perception edge’ is close to 1 to 2 dB of loudness. So 0.1 to 0.2 dB level normalization of samples is recommended.
Humans have limited time in terms of remembering an echoic memory (auditory event retaining). So time sample listening should not be too long. Immediate (real-time) easy switch between samples must be ensured.
When we compare headphones, tested samples can’t be isolated from participants technically. To solve this issue, synthesis of headphone features and comparison via single headphone units were suggested.
Measurement Precision Issue
In statistical calculations, measurement error values may be different. We don’t know if the outcome will be exact, but we must expect the initial test first approach to have a normal distribution. Therefore;
To provide measurement precision X, it is recommended to measure value Y with precision X/3 or higher.
As an example, we want to provide ear trial measurement accuracy of within 1%.
1/1% = 1/0.01 = 100 attempts
So trying a number 3 times higher 300 = 100 * 3 is recommended.
Defined measurement precision should be provided
A large number of measurements
The ear test has many variables due to the human factor above all other elements in the testing. Variation may be compensated for by using a large number of repetitions in the test a large group of participants, or a wide range of equipment items.
Big participant and test cycle number is recommended

In the “Measurement precision issue” part we considered the example: of providing 1% precision.
What we recommended were 300 cycles. However, it doesn’t guarantee 100 % accuracy. Participant skills can cause biasing of results, as an example. To compensate it with precision 1%, we should invite 300 = (1/1%)*3 = (1/0.01)*3 participants. Thus the total number of measurements is 90000 = 300 trying * 300 participants
We should take into account each feature that can possibly cause mistakes. In the initial approximation, we should invite participants with different skills, and groups of participants with the same skill should have the same number of members.
In the trial conclusions, we should group results by participant skills.
General rule:
Number measurements are enough if adding several participants and/or cycles and/or equipment items and/or other factors that will impact the results within an allowable error margin.
Careful condition control
Conditions can define the experiment. Changing conditions can bias results significantly.
Careful control of conditions provides the test exactness
Example:
Somebody wants to compare DACs. He asks people who have the devices to check it on some public HiFi test CD.
These tests, as a rule, are performed at home without an exact condition control. We have experimented with different speakers, listening places, ambient noise, etc. Even experiments, described in detail, may have subtle, at first glance, issues, that can impact upon the result.
As a rule, before experimenting we can’t know exactly what these details are or if they are important in the trial. Only the result figures can show that details are unimportant in our experiment. If they are unimportant the impact on the results will stay within an allowable error margin.
Conclusions
- Blind tests, double-blind tests, and ABX testing are intended to offer “objective” measurements of “subjective” (immeasurable) perceptions.
- Properly performed and recorded hi-fi blind tests may be able to present serious objective evidence based on subjective perception.
- The trial may be performed at home for personal purposes, but can’t be used as technical evidence.
- The trial should be designed and performed in a manner that maximizes independence from the number of participants and test cycles or both. Result deviations into the set error margin are allowable.
- The result repeatability is achieved by a large number of participants and cycles, equipment items, etc.
- Even correctly designed and performed HiFi test doesn’t guarantee absolute truth. Because new knowledge may open new details that can be incorporated into new tests.